
|
CHARACTER CODING US-ASCII - CP850 - ISO-8859-1 - CP1252 The abbreviation "ASCII" stands for: "American Standard Code for Information Interchange", ie "American Standard for Information Exchange". It was proposed in 1963 by A.N.S.I (American National Standard Institute) and became final in 1968. The ASCII code was invented for communications between teletypes (in fact there are codes of specific commands that are almost incomprehensible today but that at the time had their function), then gradually became a world standard. It was a 7-bit encoding which later, to avoid confusing it with the 8-bit extensions proposed later, was called US-ASCII. Initially the eighth bit, missing in the US-ASCII table, was used for parity checks aimed at determining transmission errors.
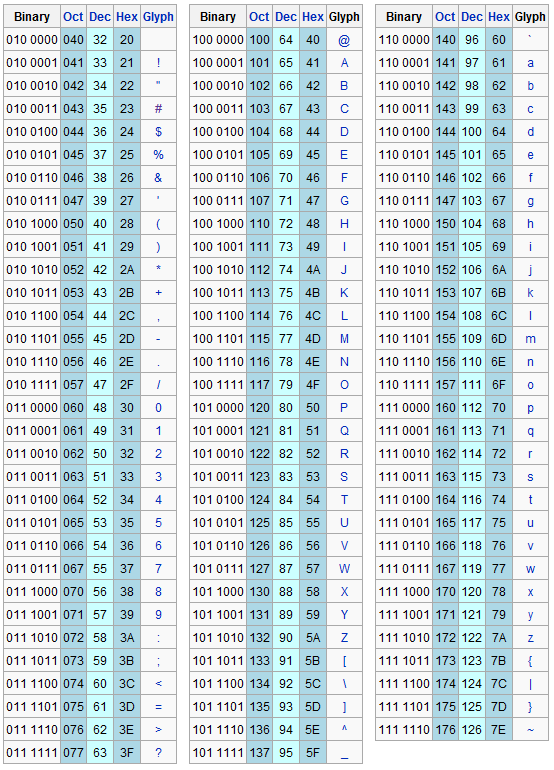
The US-ASCII encoding thus allows the numeric representation of alphanumeric characters, punctuation symbols and other symbols. The representation by numerical coding is necessary because the computer can "understand" only sequences of bits. For example, the "@" character is represented by the ASCII code "64", "Y" from the "89", "+" from the "43", etc. When someone requests information in ASCII format (for example, your resume, or an article, etc.) it means that it requires a text saved in a standard mode that is easily readable by any operating system and program.
Below the list of printable US-ASCII characters:
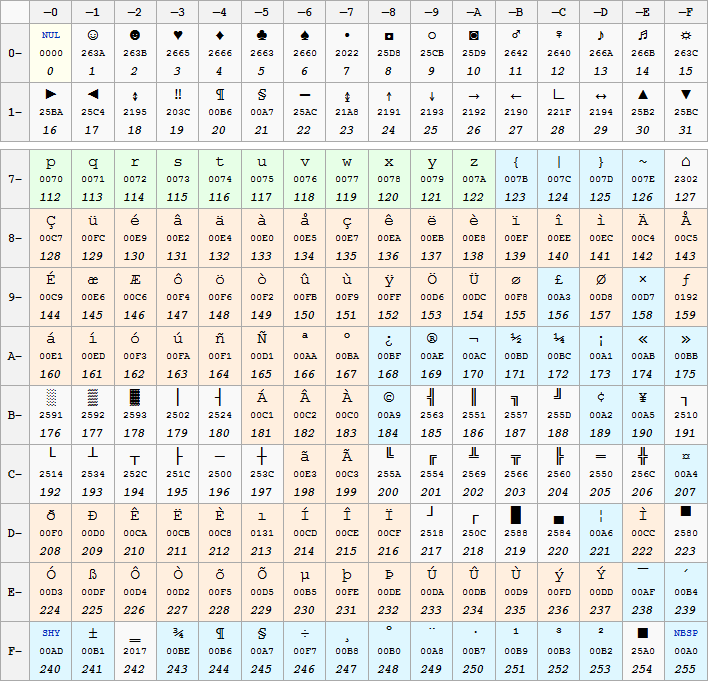
Since the number of symbols used in natural languages is much larger than the characters encoded with US-ASCII it was necessary to expand the encoding set. The various extensions used 128 additional characters that could be coded using the eighth bit available in each byte. IBM then introduced an 8-bit encoding on its IBM PCs with variants for different countries. The IBM encodings were ASCII-compatible, since the first 128 characters of the set maintained the original value (US-ASCII). The various codings were divided into pages (code page). To see the active page in DOS, use the dos chcp command. Here is the set of characters (excluding US-ASCII ones) related to code page 850
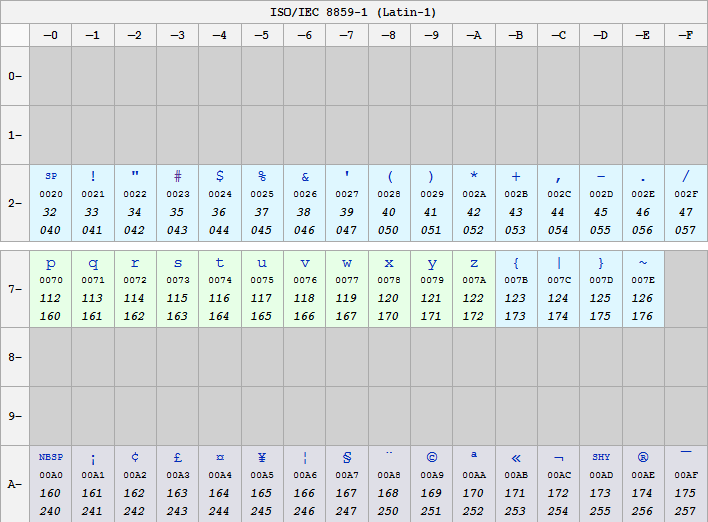
Following the proliferation of proprietary encodings, ISO released a standard called ISO / IEC 8859 containing an 8-bit extension of the ASCII set. The most important was the ISO / IEC 8859-1, also called Latin1, containing the characters for the languages of Western Europe. This specification contained for the precision the encoding of 192 graphic characters. A special feature of ISO / IEC 8859 compared to other extended characters is that characters from 128 to 159, who's lower 7 bits correspond to ASCII control characters, are not used to avoid creating compatibility problems. The codes 00-1F and 7F-9F are therefore not assigned to any character by ISO / IEC 8859-1.
The ISO / IEC 8859 standard is the starting point for the ISO-8859-1 and Windows-1252 encodings. Both codings are a subset of ISO / IEC 8859-1; Add other symbols to the 191 standard characters. ISO-8859-1 is the default encoding of HTML documents distributed using the HTTP protocol with MIME Type of the "text /" type. Many browsers and mail clients interpret ISO-8859-1 as Windows-1252 in order to fix some errors due to encoding but this is not a correct behavior and is therefore to be avoided (by those who develop browsers)
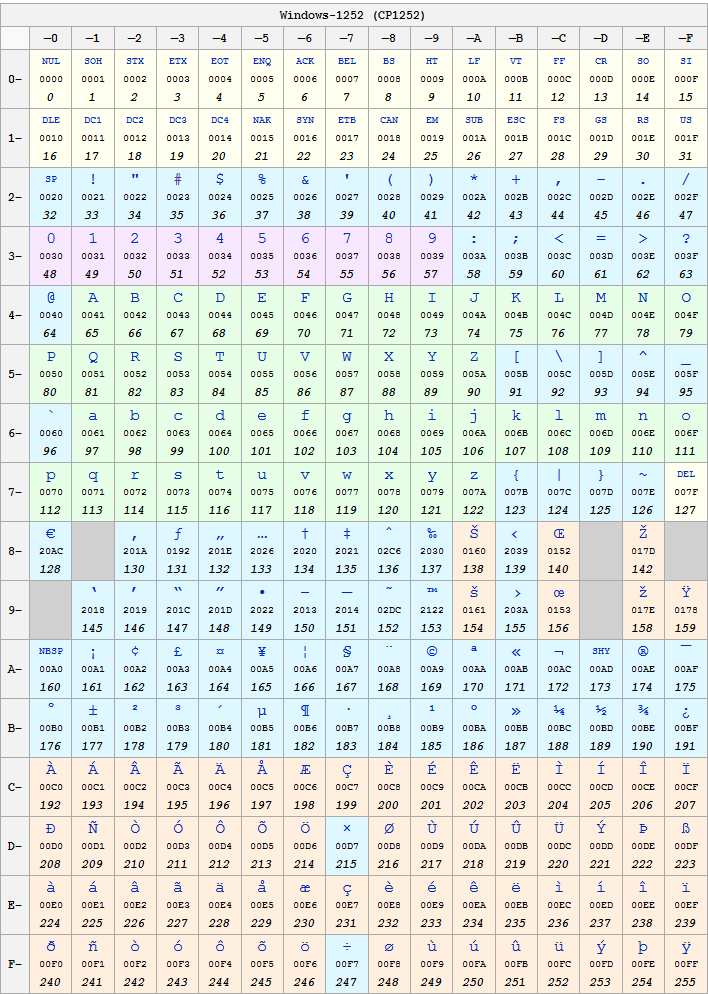
Windows-1252 was created by Microsoft (it's a set compatible with ISO 8859-1) and used as the default standard for European versions of Windows. Windows-1252 also matches ISO-8859-1 for the ranges 0x00 to 0x7F and 0xA0 to 0xFF, but not in the range 0x80 to 0x9F.
A new encoding called Unicode was developed in 1991 to be able to code more characters in a standard way and allow the use of multiple extended character sets (e.g. Greek and Cyrillic) in a single document; this set of characters is now widely used. Initially it provided for 65,536 characters (code points) and was later extended to 1,114,112 (= 220 + 216) and so far about 101,000 have been assigned. The first 256 code points follow exactly those of ISO 8859-1. Most codes are used to code languages such as Chinese, Japanese and Korean. The complete list of Unicode tables can be reached at the following link: http://www.unicode.org/charts/
www.bennypass.it |

+(39) 347 051 5328
Italy - Kazakhstan


09.00am to 18.00pm
About
We offer the best and economical solutions, backed by 27+ years of experience and international standards knowledge, echnological changes, and industrial systems.
Our Services
Marketing Materials








Marketing Materials1





